
at the AI Department of CIIRC at CTU in Prague
The Machine Learning team focuses on research in reinforcement learning, deep learning, interactive multimodal learning, hybrid intelligence, nonlinear system identification, and data analytics. We also have expertise in designing effective evolutionary and hybrid algorithms to solve hard optimization problems. Applications of our methods range from robotics through analytics software to dialog systems.
Research topics:
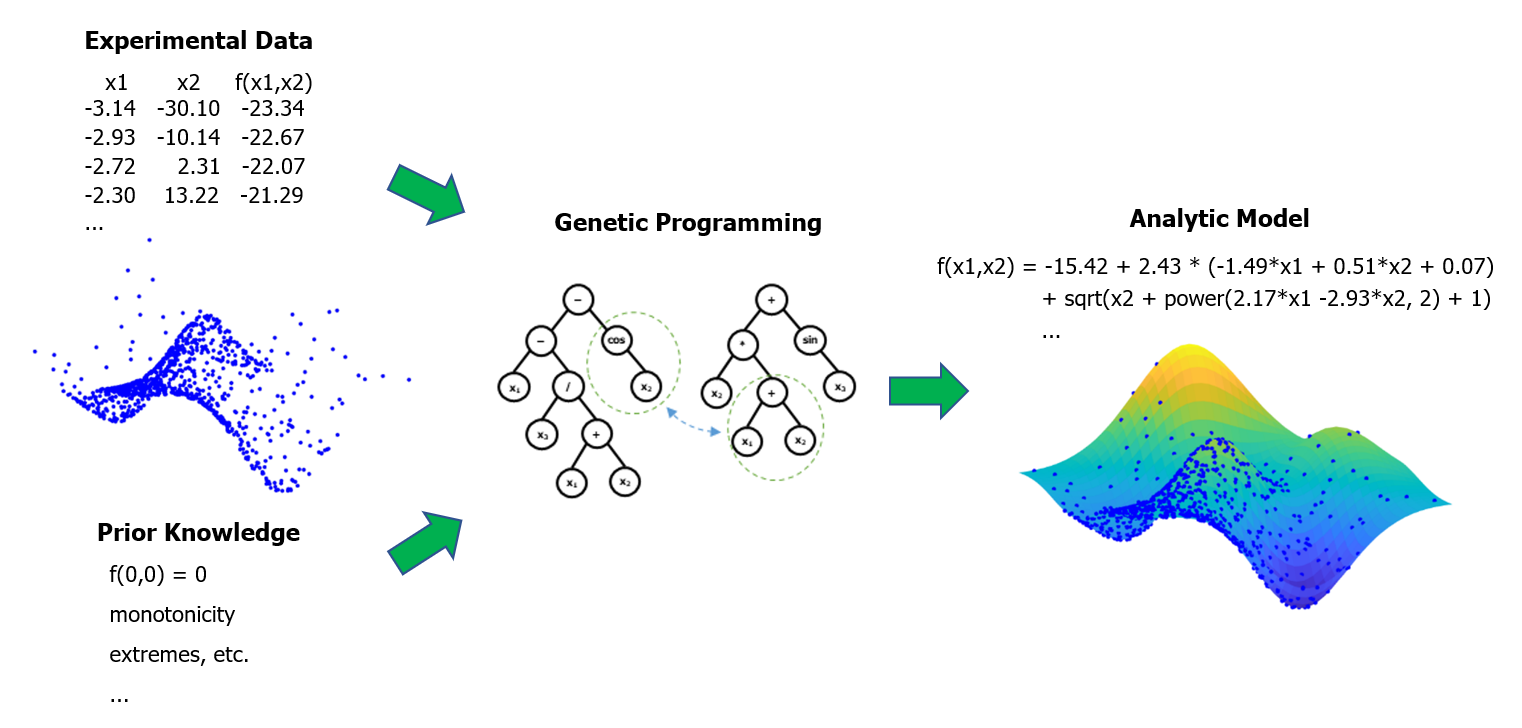
Our team has developed novel techniques for dynamic systems modeling. Specifically, we have been focusing on the design and applications of symbolic regression (SR) methods, i.e., methods that use training data to generate models in the form of analytic equations. One of the advantages over other data-driven modeling methods, such as (deep) neural networks, is that SR can construct accurate models even from very small training data sets. This is especially beneficial when a sufficiently large and informative data set is unavailable.
SR has been predominantly realized using genetic programming (GP), a gradient-free method that evolves a population of candidate models through a number of generations. We have developed several extensions to classical GP-based SR approaches. Our SR methods evolve generalized linear-in-parameters non-linear models and allow for incorporating knowledge about the desired physical properties of the sought model.
Our method produces more plausible models than standard SR in terms of the model’s compliance with, for example, the laws of physics that the modeled system must obey. Recently, we achieved very promising results with our novel methods based on heterogeneous and transformer-based neural networks.
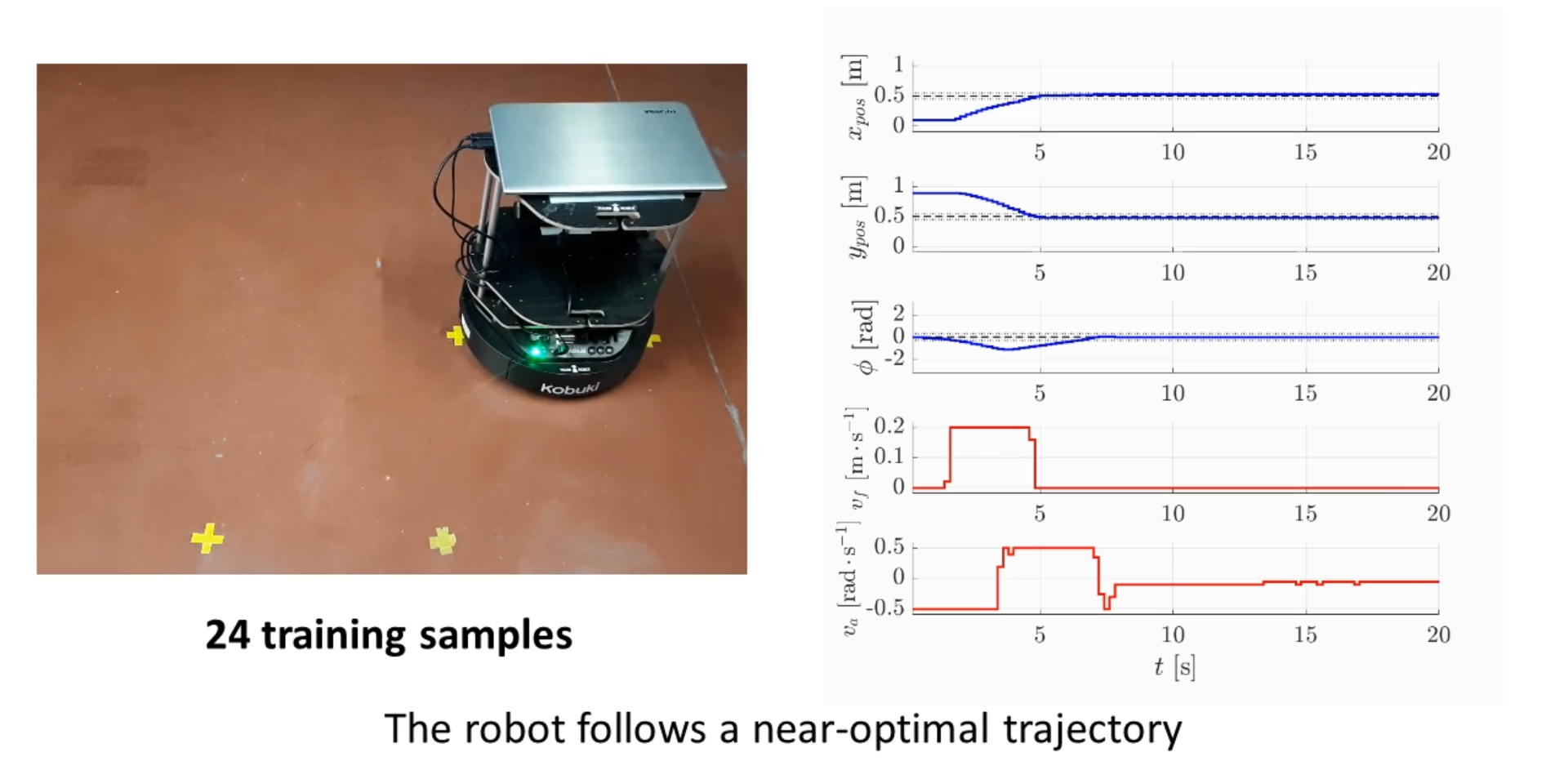
Robust and accurate model learning of the robot’s dynamics by using symbolic regression allows us to automatically find optimal control policies through model-based reinforcement learning. One of the current challenges is posed by the amount of data collected by autonomous robots during their long-term operation. Many samples are repetitive and do not bring any useful information for model learning or even negatively impact the model’s accuracy.
In our recent research, we have investigated methods for selecting informative data samples from large data buffers to make model learning more efficient and precise. We have proposed a novel method that selects informative samples based on the model’s predictive error. The method iteratively adds samples that yield the largest modeling error to the training set. Our experimental evaluation has shown that an accurate model of a real mobile robot’s dynamics can be found by running symbolic regression on a training set composed of only 24 informative samples. This model allows for optimal control of the mobile robot in a navigation task.
Visual navigation is the problem of navigating a mobile robot in an environment using a camera as the only sensor. We have developed a suite of localization, mapping, and navigation methods for mobile robots in static and dynamic environments. We employ both standard feature detectors and modern deep learning techniques, both capable of running on standard low-cost hardware available on mobile robots.
In vision-based localization and navigation, the autonomous operation of a robot may become unreliable if the changes occurring in dynamic environments are not detected and managed. To that end, we have introduced an efficient method for change detection based on weighted local visual features. The core idea is to distinguish the valuable information in stable regions of the scene from the potentially misleading information in the regions that are changing. The change detection method yields an improvement in localization accuracy compared to the baseline method without change detection. An evaluation on a public long-term localization data set shows that the proposed method outperforms widely-used alternative localization methods on images recorded many months after the initial mapping.
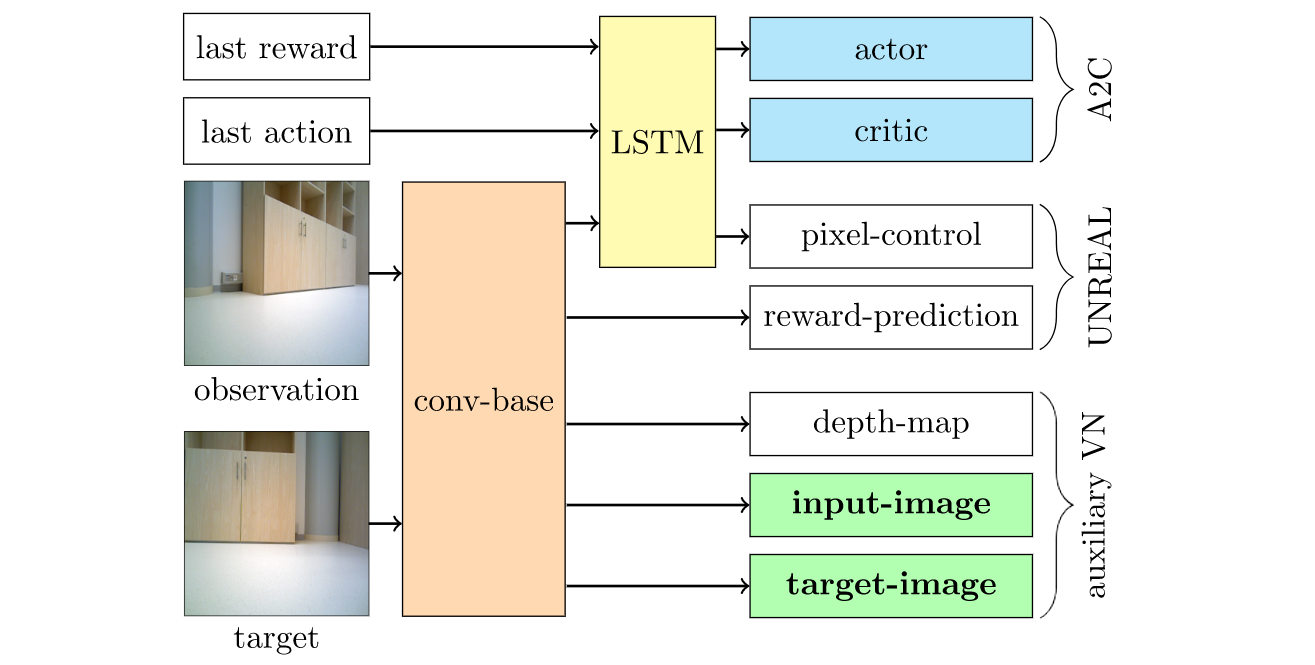
Deep reinforcement learning (DRL) is a promising approach to visual navigation when the robot has to reach a target specified via an image. We have developed a novel learning architecture with auxiliary tasks designed to improve visual navigation performance and shorten the training time. It can learn to navigate to multiple targets in several environments, surpassing the performance of state-of-the-art visual navigation methods from the literature. We have also developed methods for transferring to real-world environments by using domain randomization and auxiliary training objectives.
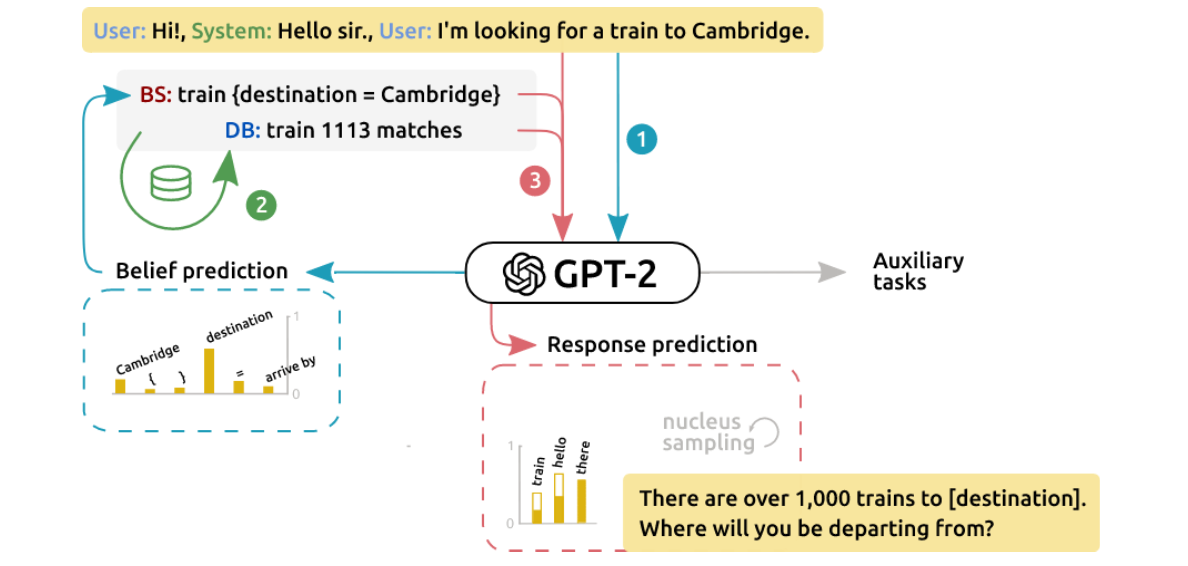
We focus on deep-learning methods for training dialog models on large corpora without manual experts’ design, common in most current systems. In collaboration with Charles University, we have developed an end-to-end task-oriented dialog system that can answer user queries in multiple domains, from restaurant recommendations through train connections to hospital information. We achieved state-of-the-art performance on the popular MultiWOZ dataset and scored high in the DSTC9 dialog competition.
An example of a dialog: User: I am looking for a cheap Chinese restaurant. Belief: restaurant {food = Chinese, price range = cheap} System: I have four cheap Chinese restaurants. In what area of town would you like to dine? User: Downtown. Belief: restaurant {area = center, food = Chinese, price range = cheap} System: I have three cheap Chinese restaurants in the center. Would you like to book at Charlie Chan? …
In our group, we research big data analytics, with an emphasis on multimedia data. II-20 is our flagship multimedia analytics system for the analytic categorization of image collections. Advanced visualizations for image collections exist, but they need tight integration with a machine model to support analytic categorization. Directly employing computer vision and interactive learning techniques gravitates towards search. Analytic categorization, however, is not machine classification (the difference between the two is called the pragmatic gap): a human adds/redefines/deletes categories of relevance on the fly to build insight, whereas the machine classifier is rigid and non-adaptive. The analytic categorization that brings the user to insight requires a flexible machine model that allows dynamic sliding on the exploration-search axis, as well as semantic interactions.
II-20 brings three major contributions to multimedia analytics on image collections and towards closing the pragmatic gap. Firstly, a machine model that closely follows the user’s interactions and dynamically models her categories of relevance. II-20’s model, in addition to matching and exceeding the state-of-the-art w. r. t. relevance, allows the user to dynamically slide on the exploration-search axis without additional input from her side. Secondly, the dynamic, one-image-at-a-time Tetris metaphor synergizes with the model. It allows the model to analyze the collection by itself with minimal interaction from the user and complements the classic grid metaphor. Thirdly, the fast-forward interaction, allowing the user to harness the model to quickly expand (“fast-forward”) the categories of relevance, expands the multimedia analytics semantic interaction dictionary. Automated experiments show that II-20’s model outperforms state-of-the-art alternatives and also demonstrate Tetris’ analytic quality. User studies confirm that II-20 is an intuitive, efficient, and effective multimedia analytics tool. II-20 is available as an open-source SW at GitHub.
